
Introduction
Large-scale reinforcement learning (RL) training of language models on reasoning tasks has emerged as a promising paradigm for mastering complex problem-solving skills.
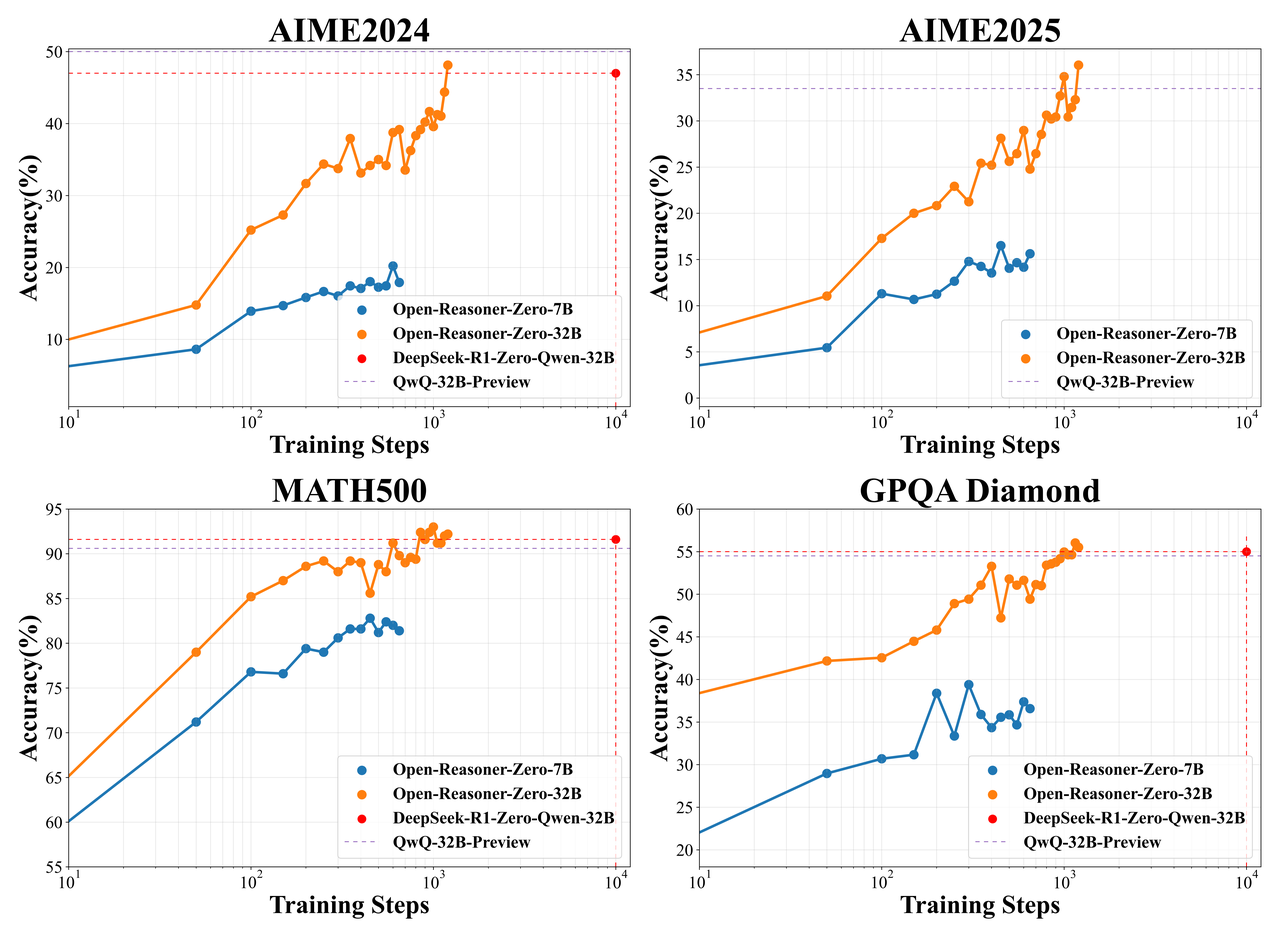
Using the same base model, Qwen2.5-32B base, as DeepSeek-R1-Zero-Qwen-32B, our Open-Reasoner-Zero-32B achieves superior performance across AIME2024, MATH500, and GPQA Diamond, while demonstrating remarkable efficiency—requiring only 1/10 of the training steps.
In the spirit of open-source, we release our source code, training data, and various model weights, fostering reproducibility and encouraging further exploration of the properties of related models.
| Model | AIME 2024 | AIME 2025 | MATH500 | GPQA Dia. |
|---|---|---|---|---|
| DeepSeek-R1-Zero-Qwen-32B | 47 | – | 91.6 | 55 |
| DAPO-Qwen-32B | 50 | – | – | – |
| DAPO-Qwen-32B* | 48.3 | 37.9 | 71.8 | 16 |
| Open-Reasoner-Zero-32B | 48.1 | 36 | 92.2 | 55.5 |
Comparison of Open-Reasoner-Zero-32B with DeepSeek-R1-Zero-Qwen-32B DAPO-Qwen-32B on reasoning-related benchmarks. DeepSeek-R1-Zero-Qwen-32B results are from ~\cite{dsr1_cite}. DAPO-Qwen-32B\textsuperscript{*} results were obtained using our evaluation metric on the released checkpoint.
| Model | MMLU | MMLU_PRO |
|---|---|---|
| Qwen2.5-32B-Base | 83.3 | 55.1 |
| Qwen2.5-32B-Instruct | 83.2 | 69.2 |
| DAPO-Qwen-32B | 79.7 | 64.5 |
| Open-Reasoner-Zero-32B | 84.9 | 74.4 |
Generalization performance of Open-Reasoner-Zero on MMLU and MMLU_PRO benchmarks. ORZ achieves superior performance on both benchmarks through RL training on reasoning tasks alone, surpassing Qwen2.5-Instruct without additional instruction tuning.
| Model | AIME 2024 | AIME 2025 | MATH500 | GPQA Dia. |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 49.1 | 93.9 | 59.1 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 60 | 94.3 | 62.1 |
| ORZ-R1-Distill-Qwen-14B | 75.2 | 60 | 95.6 | 60.4 |
We apply ORZ training recipe also to reasoning-enhanced models like DeepSeek-R1-Distill-Qwen-14B model, enabling it to grasp advanced reasoning patterns distilled from stronger reasoning models, substantially boosting its performance. This ORZ-R1-Distill-Qwen-14B achieves strong results on reasoning benchmarks, even surpassing the larger DeepSeek-R1-Distill-Qwen-32B model.
Scale-up Reinforcement Learning on a Base Model
In this section, we describe the strategy and critical components for scale-up reasoning-oriented RL directly on a base model, including algorithm choice and implementation, data curation, prompt design and reward function specification. Concretely, we show that a minimalist approach, vanilla PPO with GAE (, ) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both benchmark performance and response length.
Choosing PPO over GRPO
We adopt Proximal Policy Optimization as the RL algorithm, unlike GRPO used in DeepSeek-R1-Zero:
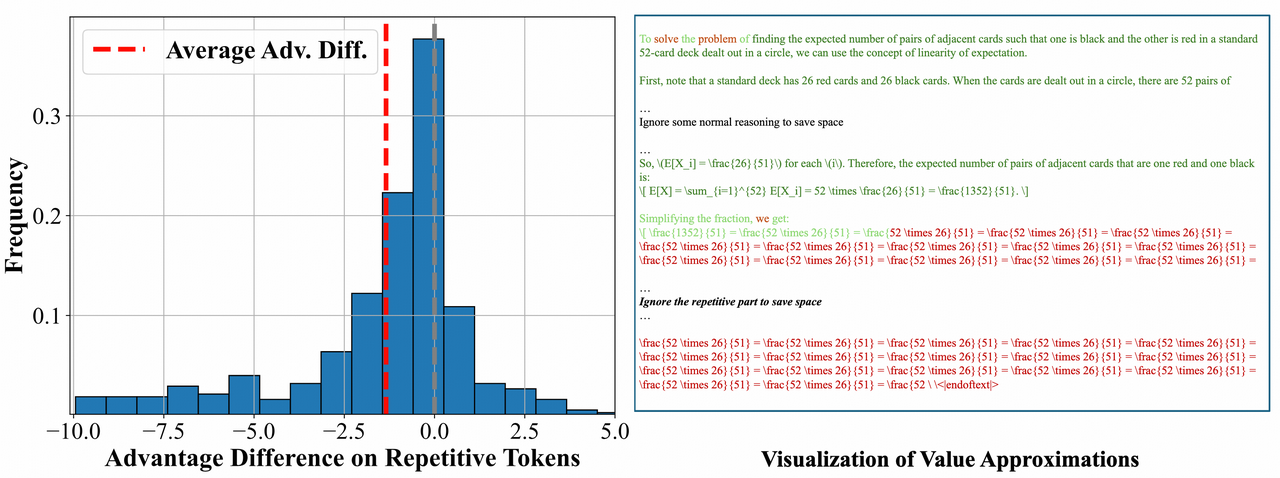
We select PPO over GRPO due to its superior value estimation enabled by a learned critic. This critic facilitates accurate token-level value estimation, effectively identifying and devaluing detrimental patterns such as repetitive behaviors, named credit assignment. Consequently, PPO achieves notably more robust advantage estimation compared to GRPO. Lacking a dedicated value network, GRPO struggles to distinguish genuinely correct responses from those occurring within negative patterns (\eg, repetitive loops). This deficiency can misdirect reinforcement, leading to training instability and eventual collapse, an observation supported by community discussions (OpenR1: discussion about vanilla GRPO reproduction link).
Algorithm Implementations
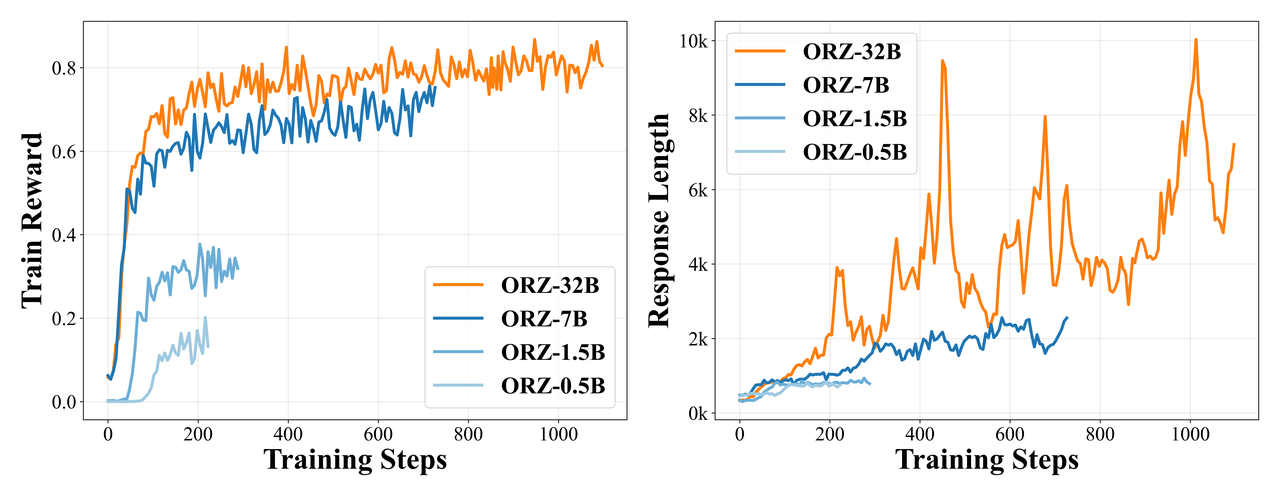
Our empirical studies suggests that vanilla PPO already provides a highly stable and robust training across different model scales and training durations.
Nonetheless, appropriate implementations matter.
Through extensive experiments, we found that the choice of GAE parameters substantially impacts performance in reasoning-oriented tasks.
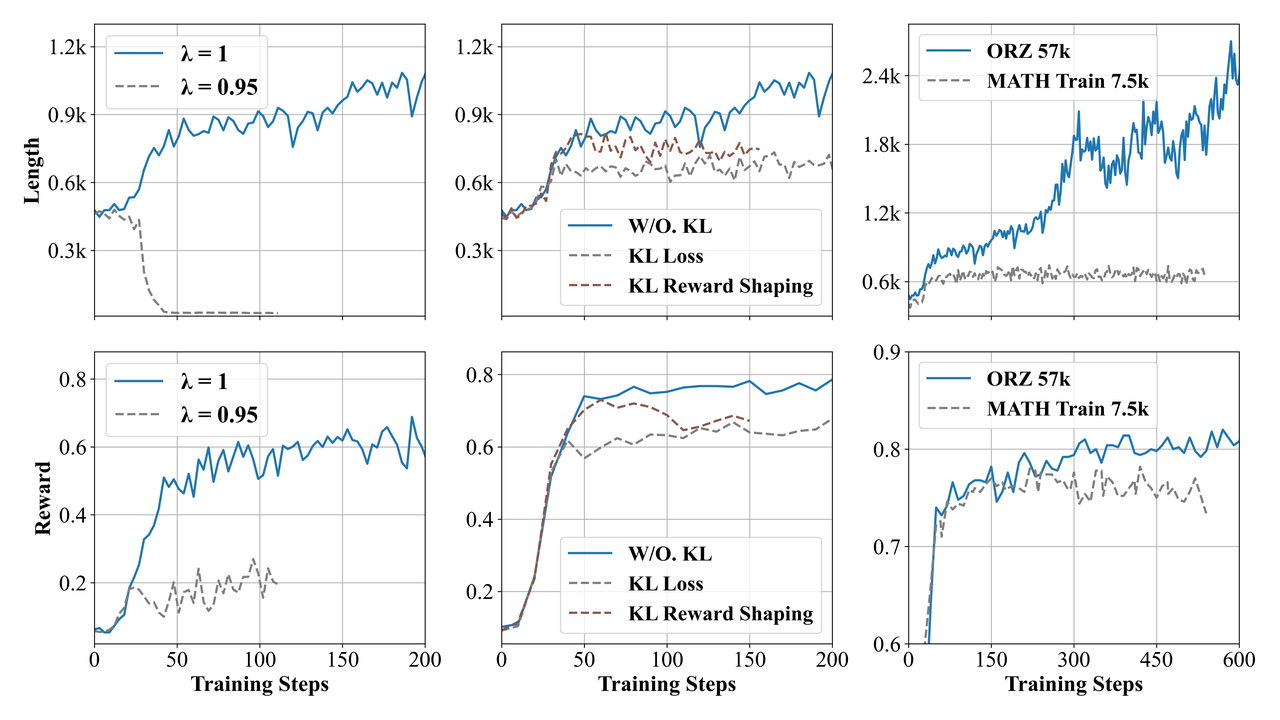
Specifically, the discount factor controls the effective sequence length considered during training: a lower assigns exponentially decreasing weights to future rewards, inducing the model to prematurely terminate generation in order to more immediately obtain rewards.
On the other hand, the GAE parameter balances bias and variance in advantage estimation. Crucially, in large-scale training scenarios, the substantial data volume naturally mitigates variance concerns, encouraging us to adopt a bias-free configuration.
Consequently, by setting and , we fully capture the long-term dependencies critical for reasoning tasks and achieve stable training.
Fortuitously, this also leads to a significant simplification of the GAE advantage computation in our case:
where is the single terminal reward.
Removing KL regularization
We achieve stable training without relying on any KL-based regularization techniques (\eg, KL shaped rewards and loss), different from the de facto RLHF community and Reasoner model. Intuitively, KL regularization constrains the policy model to remain close to the original base model distribution, potentially limiting exploration during policy optimization. By omitting KL regularization, our approach offers several practical advantages: (1) it obviates the need to navigate the large and challenging-to-tune design space inherent to KL regularization, greatly simplifying the training procedure; and (2) it lowers computational overhead and memory usage, eliminating the need to load the weight of a separate reference model and calculate log probabilities using it. Together, these benefits facilitate efficient and scalable large-scale RL training.
Scale up Training Data.
We identify that scaling up data quantity and diversity is pivotal for Reasoner-Zero training. While training on limited academic datasets like MATH train set leads to quick performance plateaus, our curated large-scale diverse dataset demonstrates impressive potential for continuous improvement without signs of saturation on both training and test sets.
Minimal Reward Function Design
In contrast to approaches such as DeepSeek R1, which utilize a dedicated format reward to enforce structured reasoning (e.g., enclosing thought processes within
Notably, even unaligned base models quickly adpot to desired format, suggesting this is a straightforward task without requiring complex reward engineering.
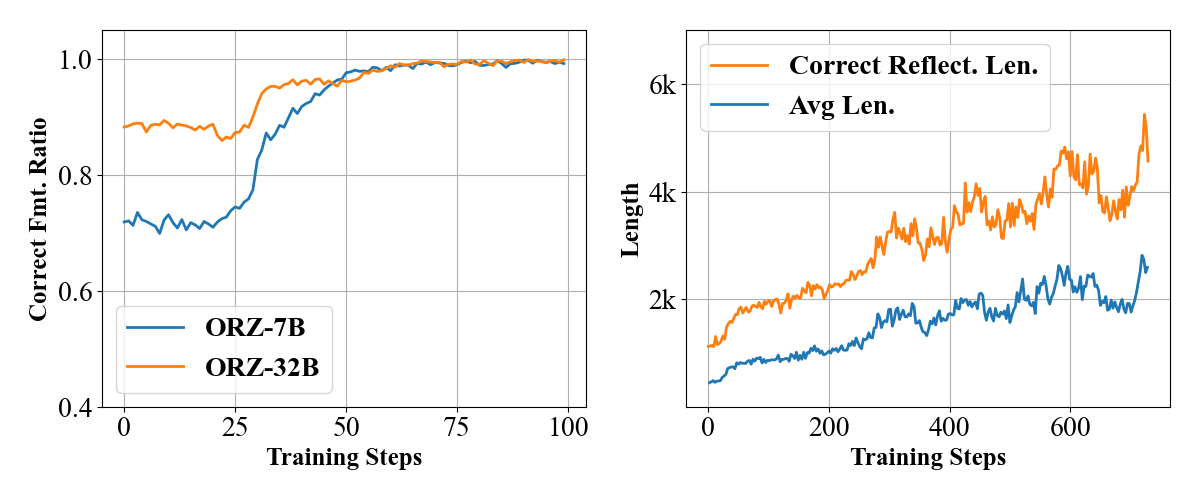
Results demonstrate rapid adoption of structured reasoning patterns even by the base model trained on a simple outcome reward function, suggesting complex reward functions are unnecessary for Reasoner-Zero. Right. Reflection patterns in generation. Average Correct Reflection Length consistently exceeds Average Response Length during training, indicating that reflection pattern can be naturally incentivized with our minimal reward design during large scale training
Use ORZ Models
You can easily start a service of ORZ-{0.5B, 1.5B, 7B, 32B} using vLLM:
You can also try out ORZ-R1-Distill-Qwen-14B:
Next Step
While Open-Reasoner-Zero (ORZ) marks a significant step forward in accessible and scalable reasoning-oriented RL, we’re excited about several avenues for future exploration:
Continuing Training-Time Scaling. Building upon the strong training-time scaling already demonstrated by ORZ, one immediate direction is to further amplify these capabilities. We plan to push these boundaries by harnessing substantially larger quantities of high-quality and diverse training data and explore extending model sequence lengths to accommodate more complex reasoning chains.
Advancing Test-Time Compute Scaling. A crucial next step is to investigate new training paradigms that can further scale up test-time compute scaling. We will explore techniques such as multi-turn interactions in multi-agent learning systems for more sophisticated contextual reasoning to tackling genuinely challenging tasks. We believe these directions will be critical in developing artificial general intelligence, and we invite the community to join us in exploring these exciting frontiers with Open-Reasoner-Zero.