Step-Audio 2:端到端语音大模型技术阶跃式突破
Step-Audio 2是一款面向工业级应用的端到端多模态大语言模型。该模型创新性地结合了隐空间音频编码器和音频强化学习技术。模型能够有效捕捉副语言信息和说话风格特征,并采用思维链(COT)推理与强化学习相结合的优化策略,Step-Audio 2实现了跨场景的高表现力语音对话能力。实验结果表明,该模型在多个理解与对话任务上均达到了当前最先进(SOTA)水平。
一、Step-Audio 2 解决的问题
大型音频语言模型(LALMs)正快速改变语音交互方式,但仍面临核心挑战:
- 语音对话中,缺失对副语言信息的有效建模:现有模型难以捕捉语调、情感、嗓音状态等副语言信息,更多在建模音频中的语义信息;即使做了副语言信息的理解,目前的方案无法有效利用这些多模信息在不同场景下完成高表现力的语音对话。
- 端到端语音对话幻觉严重:现有方案缺乏对真实世界文本知识和音频知识的有效访问,模型幻觉严重。
Step-Audio 2通过三大创新解决这些痛点:
- 真端到端多模态架构:“真”端到端,直接处理原始音频,保证对副语言信息和非人声信息的有效理解。
- CoT 推理结合强化学习:首创音频推理能力,能对情绪、副语言、音乐等非文字信号进行精细理解、推理并进行自然回应。
- 音频知识增强:使用包括web检索和音频检索在内等外部工具,解决幻觉问题,同时赋予模型通过音色检索无缝切换音色风格的能力。
样例展示
你好,我是小跃,你的智能助手小伙伴
贴心伙伴-副语言理解能力
辨声专家-声音识别分析能力
智商达人-学习能力&计算能力
语言天才-多语言&方言理解与表达能力
百变音色-Voice Rag能力
故事妙手-文本创作能力&语言表达能力
情感大师-语音对话推理能力
二、技术路线优势:创新与突破
相比行业现有方案,Step-Audio 2通过以下技术创新解决核心痛点:
2.1 架构突破
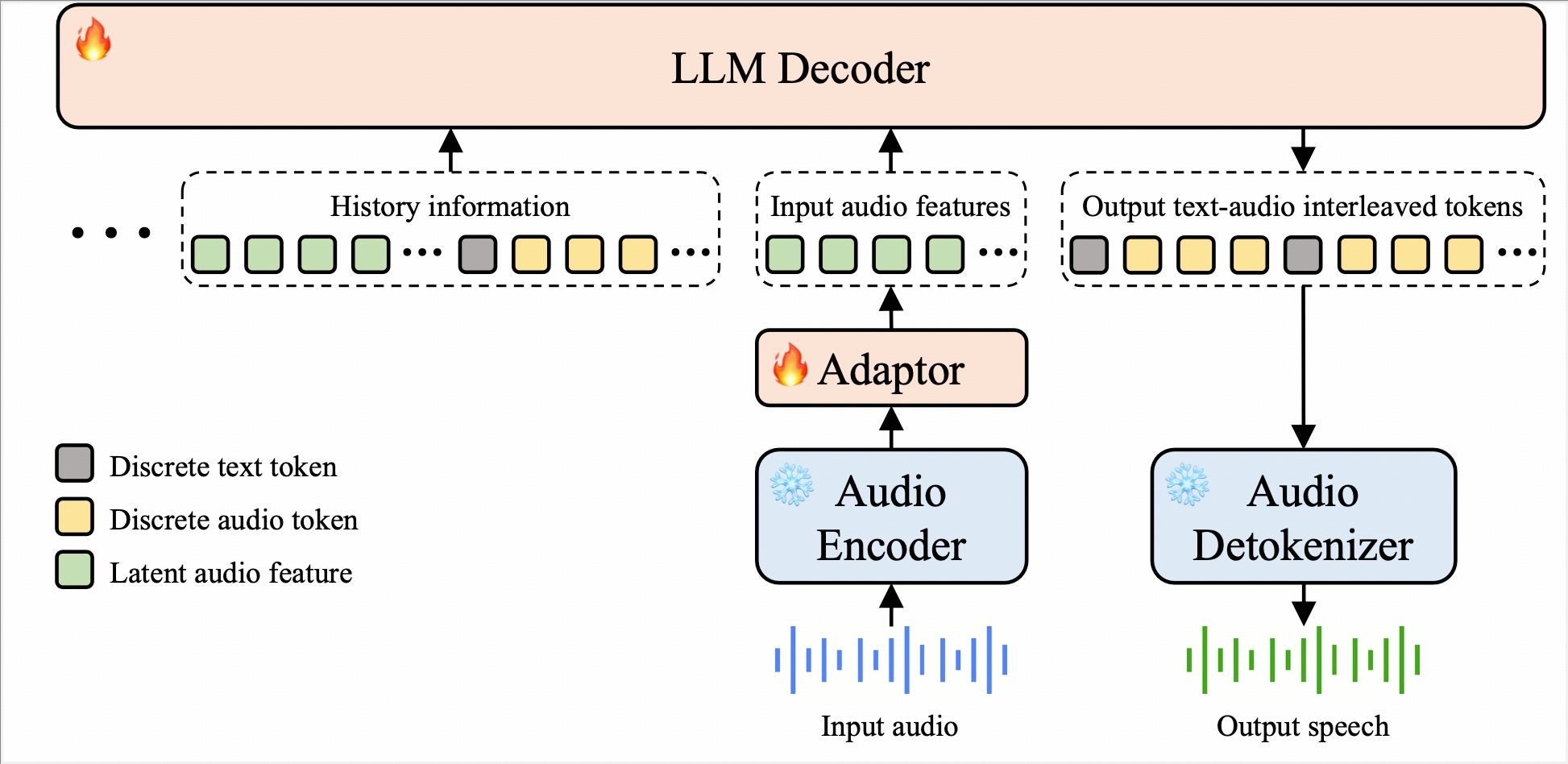
- 真端到端语音模型 ⇨ 突破传统ASR + LLM + TTS三级结构,实现原始音频输入→语音响应输出的直接转换; ⇨ 时延更低,架构更简单。
- 连续输入+离散输出范式 ⇨ 直接处理原始音频波形,避免特征提取造成的信息损失 ⇨ 通过离散音频token保证声音合成稳定性
- 文本+语音token交错 ⇨ 在语言建模层实现文本与语音token的固定比例交错排列 ⇨ 确保文本-语音模态高度对齐,保证模型的智商上限。
2.2 数据工程创新
- 千万小时级训练音频数据 ⇨ 千万小时真实语音数据训练,覆盖多语种、多场景、多设备环境
- 高质量情感对话数据合成链路
2.3 核心功能亮点
- 音频深度推理能力(Audio Reasoning)
⇨ 业界领先的细粒度音频理解:
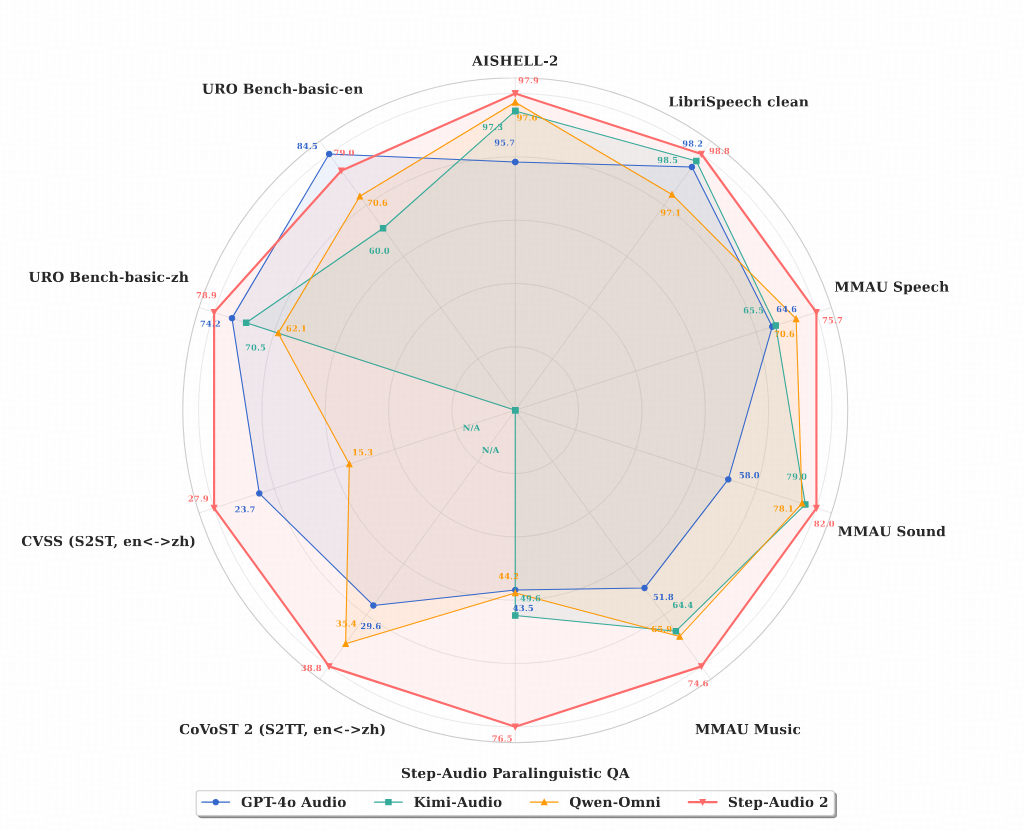
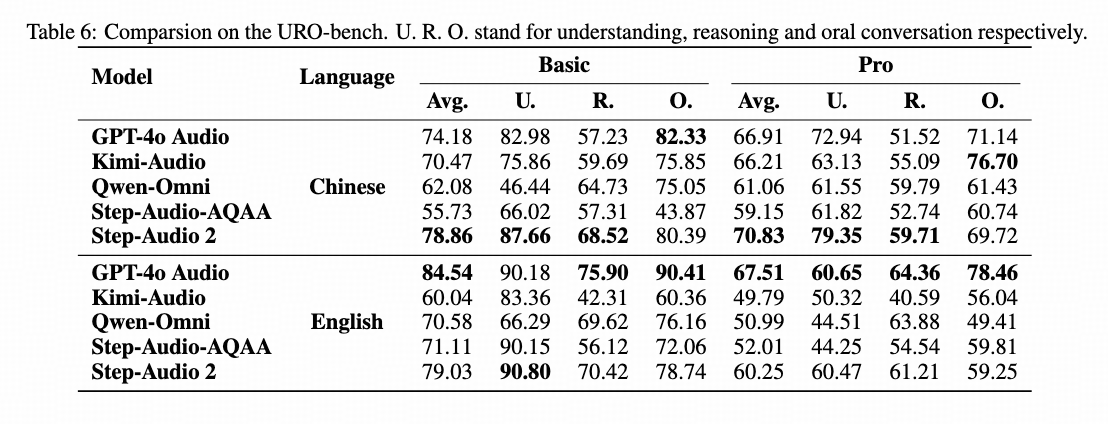
- 中文语音对话场景中以78.86的分数取得SOTA(URO-Bench)
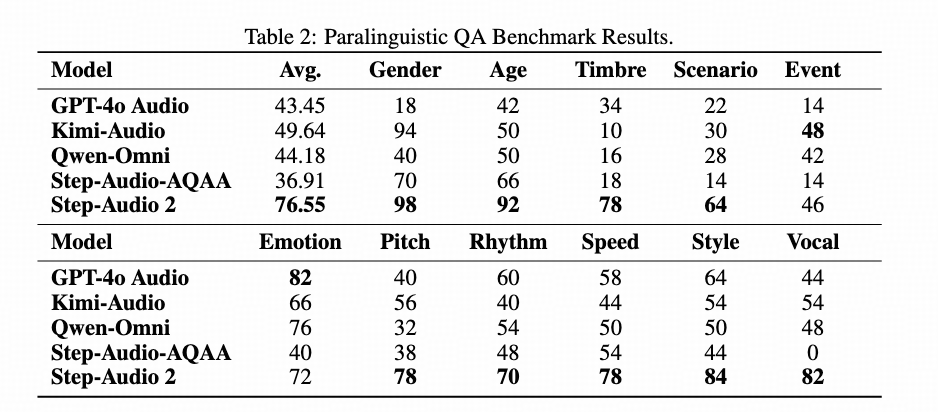
- 11类副语言特征理解准确率76.55%,远超其他模型(Step-SPQA)
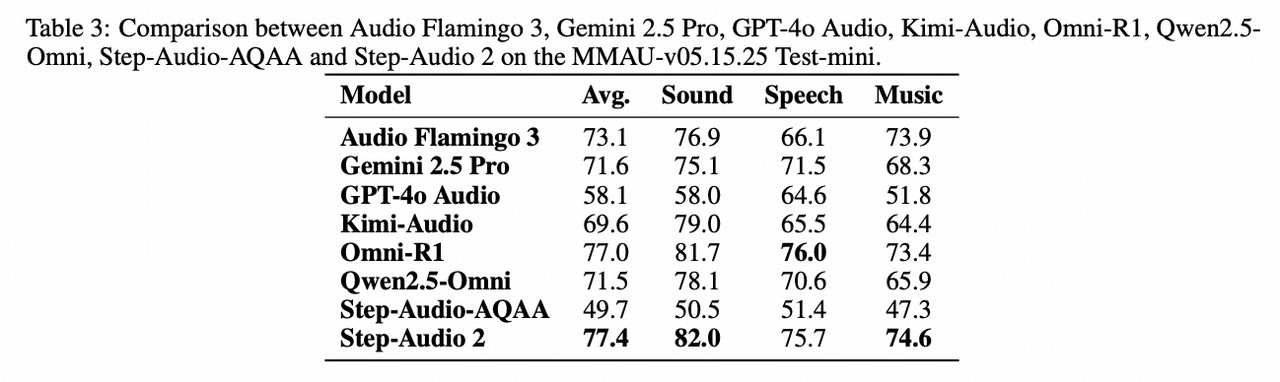
- 多种音频理解任务评价得分77.4%(MMAU Benchmark),超过GPT-4o-Audio以及Gemini-2.5-Pro
- 对话中实时音色切换 ⇨ 突破性支持语音指令触发音色切换
三、如何快速体验 Step-Audio 2
下载最新版本阶跃AI App,在首页右上角点击电话按钮即可与 Step-Audio 2 对话!
四、榜单成绩
- 公开榜单
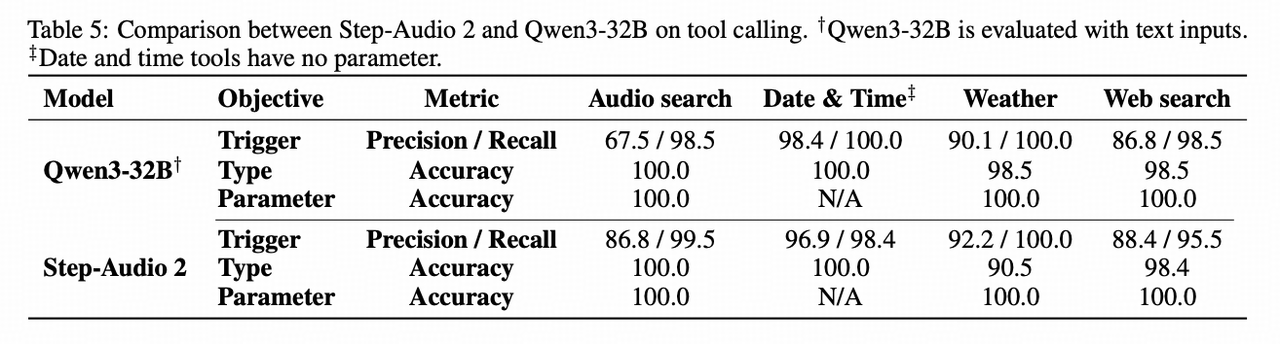
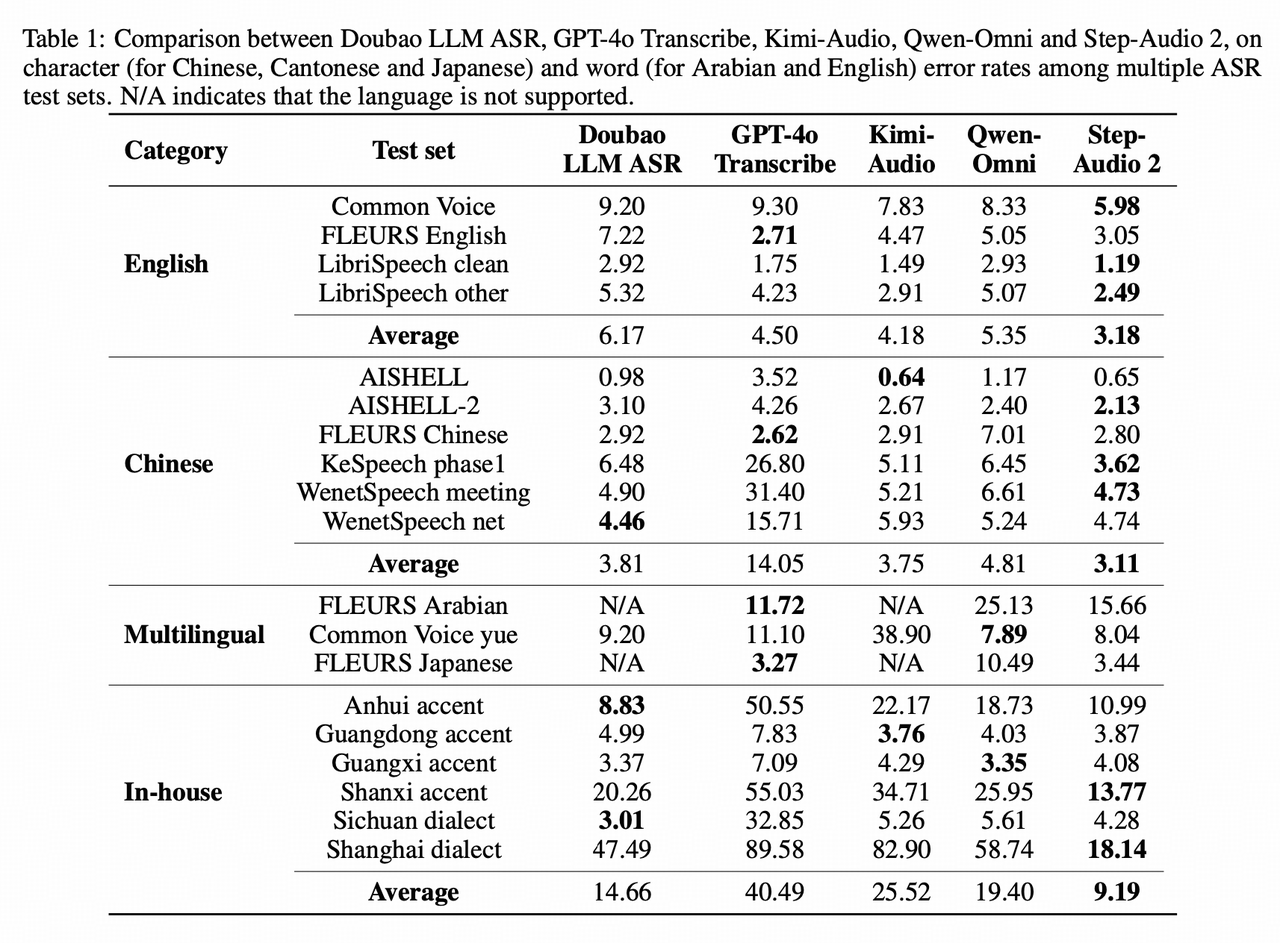
- ASR多个Benchmark SOTA:
- 英文Common Voice/LibriSpeech 国际第一,Fleurs-en国内第一;
- 中文AISHELL-2/KeSpeech(重口音)/WenetSpeech国际第一,Fleurs-zh国内第一;
- MMAU:国际第一,超过GPT-4o-Audio、Gemini-2.5-Pro、英伟达最新的Audio Flamingo3,以及专用小模型Omni-R1;
- URO-bench:中文国际第一,英文国内第一;
- 自建榜单
- Step-SPQA,业内首个副语言理解的Benchmark,国际第一
- Step-AudioToolcall,一个语音Toolcall Benchmark,业界首个语音Toolcall Benchmark。