
强化学习优化语言模型预训练
2025/06/10·StepFun can make mistakes, check important info.
解读一下
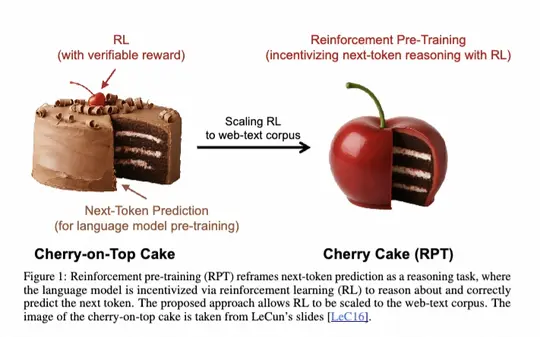
这张图展示了一种名为“Cherry-on-Top Cake”(樱桃在上蛋糕)的概念,它代表了一种使用强化学习(Reinforcement Learning,RL)进行预训练的语言模型方法。
图示解读:
-
Cherry-on-Top Cake(樱桃在上蛋糕):
- 这部分表示一个标准的预训练语言模型,它通过**Next-Token Prediction(下一个词预测)**任务进行训练。
- 目标是预测给定文本序列中的下一个词。
-
Reinforcement Pre-Training(强化预训练):
- 这部分展示了如何使用强化学习来改进预训练过程。
- 通过将Next-Token Prediction重新定义为一种推理任务,语言模型被激励使用强化学习来思考和正确地预测下一个词。
- 这个方法被称为“Cherry Cake(RPT)”,它结合了强化学习的奖励机制来优化模型的预测能力。
-
Scaling RL to web-text corpus(将强化学习扩展到网络文本语料库):
- 图中展示了从Cherry-on-Top Cake到Cherry Cake(RPT)的转变,表示将强化学习的方法扩展到更大的网络文本语料库中。
- 这允许模型在更广泛的数据上进行训练,并进一步提高其性能。
关键概念:
- Next-Token Prediction(下一个词预测):这是语言模型预训练的标准任务,模型通过预测给定文本序列中的下一个词来学习语言的统计规律。
- Reinforcement Learning(强化学习):一种机器学习方法,通过与环境交互并接收奖励信号来学习最优行为。在语言模型中,强化学习可以用于优化模型的预测能力。
- Reinforcement Pre-Training(强化预训练):一种结合了强化学习和预训练的方法,旨在提高语言模型的预测能力和泛化能力。
总结:
这张图展示了一种名为“Cherry Cake(RPT)”的新型预训练方法,它使用强化学习来改进语言模型的Next-Token Prediction能力。通过将预测任务重新定义为推理任务,并使用强化学习的奖励机制来优化模型,Cherry Cake(RPT)能够更好地捕捉语言的统计规律,并在更广泛的数据上进行训练。这有望提高语言模型的性能和泛化能力。