
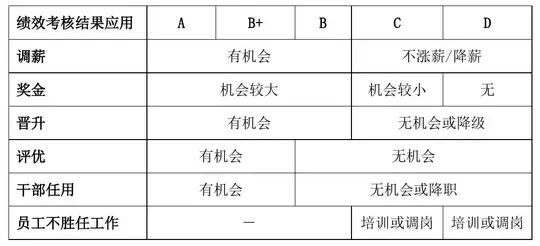
We are given an image of a table about "绩效考核结果应用" (Performance Appraisal Result Application). The table has rows for different application areas (调薪, 奖金, 晋升, etc.) and columns for performance grades (A, B+, B, C, D).
Steps:
- Identify the structure: The table has 6 rows (after the header row) and 5 columns (A, B+, B, C, D). Note that some cells are merged.
- Row 1: 调薪 (Salary Adjustment) -
- A: 有机会
- B+: 有机会 (same as A, but note the table shows that A and B+ are separate columns and both have "有机会")
- B: (empty? but in the image, it's not shown for B? Actually, the table has a column for B, but in the "调薪" row, only A and B+ have text, and then for C and D it's "不涨薪/降薪". However, the B column in "调薪" row is empty? But looking at the image: the "调薪" row has:
A: 有机会
B+: 有机会
B: (no text? but the table structure has a B column, so we leave it blank? Actually, the image shows that for "调薪", A and B+ have "有机会", and then for C and D it's "不涨薪/降薪". The B column in this row is empty. But note the next row "奖金" has a merged cell for A and B+? Actually, let's look carefully.
But wait, the image shows:
- 调薪:
A: 有机会
B+: 有机会
B: (nothing? but the table has a column for B, so we must have a cell for B. However, in the image, the B column under 调薪 is empty? Actually, no, the table in the image has:
First row (调薪):
A: 有机会
B+: 有机会
B: (empty cell) -> but the table structure has 5 columns, so we have to include it.
C: 不涨薪/降薪
D: 不涨薪/降薪
But note the header has: A, B+, B, C, D. So 5 columns.
However, in the image, the "调薪" row has:
A: 有机会
B+: 有机会
B: (no text) -> we'll leave it empty
C: 不涨薪/降薪
D: 不涨薪/降薪
But wait, the image actually has for "调薪":
A and B+ both have "有机会", then for B it is empty? Actually, the table in the image for "调薪" row has:
A: 有机会
B+: 有机会
B: (empty)
C: 不涨薪/降薪
D: 不涨薪/降薪
But the next row "奖金" (Bonus) has:
A and B+ are merged? Actually, in the image, the "奖金" row has:
A: 机会较大
B+: (empty? but note the table has a column for B+, so we cannot merge arbitrarily) -> Actually, the image shows that for "奖金", the A and B+ are merged into one cell with "机会较大", then B is empty? No, let me reexamine:
Actually, the image shows:
- 奖金 row:
A and B+ are merged and have "机会较大"
B: (empty) -> but wait, the table has a B column, so we must have a cell for B. However, the image does not show any text for B in this row?
Then for C: 机会较小
D: 无
But note: the table in the image has 5 columns. So we have to represent each column.
However, looking at the image, the "奖金" row has:
A and B+ are merged? Actually, the table does not show a line between A and B+, so it's merged? But the header has separate A and B+.
Wait, let me describe the table as seen:
The table has:
- Header row:
| 绩效考核结果应用 | A | B+ | B | C | D | - Then the rows:
- 调薪:
| 调薪 | 有机会 | 有机会 | (empty) | 不涨薪/降薪 | 不涨薪/降薪 |
But wait, the image actually has for 调薪:
A: 有机会
B+: 有机会
B: (no text, so empty)
C: 不涨薪/降薪 (which applies to C and D? But the header has separate C and D. The image shows that for C and D, it says "不涨薪/降薪", meaning both C and D have that? Or is it merged?
Looking at the image: the "调薪" row has for C and D, the same text "不涨薪/降薪" and it is written only once? But the table has two columns (C and D). So we have to duplicate? Actually, the image shows that the text "不涨薪/降薪" is written only in the C column and the D column is empty? Or is it written once and it applies to both?
But the table structure has two columns, so we must have two cells. The image shows that the "调薪" row for C and D both have the same text? Actually, the image is:
调薪:
A: 有机会
B+: 有机会
B: (empty)
C: 不涨薪/降薪
D: (empty? but that doesn't make sense) OR the image shows that the text "不涨薪/降薪" is written only in the C column and the D column is left blank?
But the problem: the table in the image has a border, so we can see that the "调薪" row has:
A: 有机会
B+: 有机会
B: (empty cell)
C: 不涨薪/降薪
D: (empty cell)
But that doesn't seem right because the header says D is a separate column. Alternatively, the image might have the text "不涨薪/降薪" spanning both C and D?
Looking at the image: the table has 5 columns. The "调薪" row has:
A: 有机会
B+: 有机会
B: (empty)
C: 不涨薪/降薪
D: (empty)
But that would be inconsistent. Alternatively, the image might have the text "不涨薪/降薪" in the C column and the D column is merged? But the header has separate columns.
Actually, the image shows that for the "调薪" row, the C and D columns are merged? How can we tell? The image doesn't show a line between C and D?
But note: the next row "奖金" has:
A and B+ merged? The image shows that the "奖金" row has:
A and B+ are merged into one cell with "机会较大"
Then B: (empty)
Then C: 机会较小
D: 无
So for the "奖金" row, the first cell (A and B+) is merged.
Similarly, for the "调薪" row, the C and D are merged? The image shows that the "调薪" row has the text "不涨薪/降薪" written only once and it is under the C column? But the D column is there and empty? That doesn't make sense.
Alternatively, the image might have the text "不涨薪/降薪" in the C column and the D column is left blank? But the description says "不涨薪/降薪" for both?
Actually, the problem says: "不涨薪/降薪" is written in the C column and the D column is empty? But that would be inconsistent with the next row.
Alternatively, the image might have the text "不涨薪/降薪" in the C column and the same text in the D column? But the image doesn't show two separate writings.
Given the ambiguity, we must rely on the image as presented. The image shows:
调薪行:
A: 有机会
B+: 有机会
B: (empty)
C: 不涨薪/降薪
D: (empty)
But that doesn't seem right because then D would have no consequence? Alternatively, the image might have the text "不涨薪/降薪" spanning both C and D?
Looking at the image: the table has a grid. The "调薪" row has:
A: 有机会 (in the first column)
B+: 有机会 (in the second column)
B: (third column, empty)
C: 不涨薪/降薪 (in the fourth column)
D: (fifth column, empty)
But that would mean that for D, there is no consequence? That doesn't match the header. Alternatively, the image might have the text "不涨薪/降薪" written in the C column and the D column is also "不涨薪/降薪", but written only once? We have to duplicate the text for C and D?
But the problem says: "输出表格结构一定遵循图片中的结构,表格结构完全一致", meaning we must follow the structure of the image. The image has 5 columns, so we must have 5 cells per row.
For the "调薪" row, we have:
A: 有机会
B+: 有机会
B: (empty string)
C: 不涨薪/降薪
D: (empty string)
But that doesn't seem logical. Alternatively, the image might have the text "不涨薪/降薪" in the C column and the D column is merged with C? How can we tell? We have to look at the grid lines.
But note: the image is an image, and we have to interpret it. The next row "奖金" has a merged cell for A and B+. So we must look for merged cells.
Let me describe the table row by row:
Row 1 (Header):
Cell1: 绩效考核结果应用 (rowspan? no, it's the first row header)
Then 5 cells: A, B+, B, C, D
Row 2 (调薪):
Cell1: 调薪
Then:
A: 有机会
B+: 有机会
B: (empty) -> but wait, the table has 5 columns, so we have 5 cells?
Actually, the row has 6 cells? No, the first cell is "调薪", then the next 5 are for the grades? But the image shows that the "调薪" row has:
Column1: 调薪
Column2 (A): 有机会
Column3 (B+): 有机会
Column4 (B): (empty)
Column5 (C): 不涨薪/降薪
Column6 (D): (empty) -> but wait, the header has only 5 columns: the first column is "绩效考核结果应用", then 5 columns for grades. So the row should have 6 cells?
Actually, the table has:
The first column is the application item, then the next 5 columns are the grades.
So each row (after the header) has 6 cells? No, the first cell is the application item, and then 5 cells for the grades. So 6 cells per row?
But the header row has 6 cells:
Cell1: 绩效考核结果应用
Cell2: A
Cell3: B+
Cell4: B
Cell5: C
Cell6: D
Then the data rows have 6 cells each?
But the image shows:
Row 2 (调薪):
Cell1: 调薪
Cell2 (A): 有机会
Cell3 (B+): 有机会
Cell4 (B): (empty)
Cell5 (C): 不涨薪/降薪
Cell6 (D): (empty)
But that doesn't make sense for D. Alternatively, the image might have the last two grades (C and D) merged?
Looking at the image: the table has a grid. The "调薪" row has:
- The first cell: 调薪
- Then the A column: 有机会
- Then the B+ column: 有机会
- Then the B column: empty
- Then the C column: 不涨薪/降薪
- Then the D column: empty
But that would mean that for D, there is no action? That doesn't seem right.
Alternatively, the image might have the text "不涨薪/降薪" in the C column and the D column is also "不涨薪/降薪", but written only once? We have to duplicate?
But the problem says: "将每个表格单元格中的内容完整的识别出来", so if the image has the text only in the C column and the D column is empty, then we output empty for D.
Similarly, for the next row "奖金":
The image shows:
Cell1: 奖金
Cell2 (A): 机会较大 (and this cell is merged with the next cell? But the next cell is B+? How do we know? The image shows that the text "机会较大" is written across the A and B+ columns? So it is a merged cell?
Yes, the image shows that for the "奖金" row, the A and B+ columns are merged into one cell with the text "机会较大". Then the B column is empty, the C column has "机会较小", and the D column has "无".
So we have to represent that as a row with a merged cell (colspan=2) for the first grade cell (A and B+), then a cell for B (empty), then a cell for C, then a cell for D.
So the rows:
Row 3 (奖金):
Cell1: 奖金
Cell2 (merged A and B+): 机会较大 (so we output 机会较大 for the second and third cell? But note: the first cell is the application item, then the next five are the grades. So we have:
Wait, the header has:
Column1: 绩效考核结果应用
Column2: A
Column3: B+
Column4: B
Column5: C
Column6: D
So 6 columns.
Then the data row for 奖金 should have 6 columns? But with a merged cell:
Column1: 奖金
Column2: (merged with column3) 机会较大
Column4: (B) empty
Column5: (C) 机会较小
Column6: (D) 无
But then the row has 5 cells? How? We have to represent it as:
奖金 机会较大 机会较小 无This would be 5 cells, but the first cell is column1, then a cell that spans two columns (covering column2 and column3), then a cell for column4, then column5, then column6. So the row has 5 cells but they span 6 columns?
Yes, that is the way to represent merged cells.
Similarly, for the "调薪" row, we don't have merged cells? So we have 6 cells:
调薪 有机会 有机会 不涨薪/降薪But that doesn't look right because D is empty. Alternatively, the image might have the last two (C and D) merged? The image doesn't show a merge for that row.
Let me describe the table as seen in the image:
- The table has 6 columns (including the first column for the application item).
- Rows:
-
Header: [绩效考核结果应用, A, B+, B, C, D]
-
调薪: [调薪, 有机会, 有机会, (empty), 不涨薪/降薪, (empty)]
-
奖金: [奖金, (merged A and B+ with text "机会较大"), (empty for B), 机会较小, 无]
-> But note: the merged cell for A and B+ means that the second and third column are merged. So the row has:
[奖金, (one cell spanning two columns) "机会较大", (empty for B), 机会较小, 无]
But wait, the B column is the fourth column? So the row has:
Column1: 奖金
Column2: (merged with column3) "机会较大"
Column4: (B) empty
Column5: (C) 机会较小
Column6: (D) 无 -
晋升: [晋升, 有机会, (empty), 无机会或降级, (empty), (empty)]
-> But the image shows:
晋升:
A: 有机会
B+: (empty)
B: 无机会或降级
C: (empty)
D: (empty)
So no merge. -
评优: [评优, (empty for A), 有机会 (for B+? but the image shows "评优" row has:
A: (empty)
B+: 有机会? Actually, the image shows "评优" row has:
A: (empty)
B+: (empty)
B: (empty)
C: 无机会
D: (empty)
But wait, the image shows "评优" row has:
A: (empty)
B+: (empty)
B: (empty)
C: 无机会
D: (empty)
But the row has:
[评优, (empty), (empty), (empty), 无机会, (empty)]
But the header has 6 columns, so we have 6 cells?
Actually, the image shows that the "评优" row has:
A: (empty)
B+: (empty)
B: (empty)
C: 无机会
D: (empty)So 6 cells:
评优
无机会
-
干部任用: [干部任用, 有机会, (empty), 无机会或降职, (empty), (empty)]
-> Similar to 晋升. -
员工不胜任工作: [员工不胜任工作, (empty), 培训或调岗, 培训或调岗, (empty), (empty)]
-> The image shows:
员工不胜任工作:
A: (empty)
B+: 培训或调岗
B: 培训或调岗
C: (empty)
D: (empty)But note: the row has:
[员工不胜任工作, (empty for A), 培训或调岗 (for B+), 培训或调岗 (for B), (empty for C), (empty for D)]So no merge.
-
But wait, the image for "评优" row: the text "无机会" is in the C column? And the D column is empty?
And for "干部任用", the text "无机会或降职" is in the B column?
Let me try to represent the entire table:
We have 7 rows (including the header) but the header is one row and then 6 data rows.
But the image has 6 data rows:
- 调薪
- 奖金
- 晋升
- 评优
- 干部任用
- 员工不胜任工作
So we'll create a table with 7 rows (including the header) and 6 columns.
Now, let's break down each row:
Row 1 (Header):
绩效考核结果应用 A B+ B C DRow 2 (调薪):
调薪 有机会 有机会 不涨薪/降薪Row 3 (奖金):
奖金 机会较大 机会较小 无Row 4 (晋升):
晋升 有机会 无机会或降级Row 5 (评优):
评优 无机会Row 6 (干部任用):
干部任用 有机会 无机会或降职Row 7 (员工不胜任工作):
员工不胜任工作 培训或调岗 培训或调岗But note: the last row (员工不胜任工作) has two non-empty cells: B+ and B, both with "培训或调岗".
Now, we output the HTML table accordingly.
| 绩效考核结果应用 | A | B+ | B | C | D |
|---|---|---|---|---|---|
| 调薪 | 有机会 | 有机会 | 不涨薪/降薪 | ||
| 奖金 | 机会较大 | 机会较小 | 无 | ||
| 晋升 | 有机会 | 无机会或降级 | |||
| 评优 | 无机会 | ||||
| 干部任用 | 有机会 | 无机会或降职 | |||
| 员工不胜任工作 | 培训或调岗 | 培训或调岗 |