
RAG系统架构解析
2025/08/15·StepFun can make mistakes, check important info.
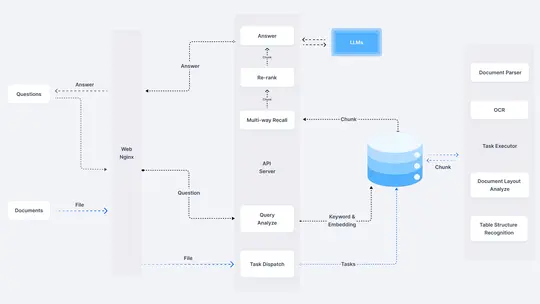
请解释这个rag系统架构图
这个图展示了一个检索增强生成(RAG)系统的架构。以下是各个组件及其功能的解释:
1. 输入组件
- Questions: 用户输入的问题。
- Documents: 用户上传的文档文件。
2. Web Nginx
- 作为系统的前端服务器,负责处理外部的请求,例如问题和文件的输入。
3. API Server
- Query Analyze: 对用户的问题进行分析,提取关键词和生成问题的嵌入(Embedding)。
- Task Dispatch: 根据分析的结果,将任务分发给相应的处理模块。
- Multi-way Recall: 通过多种方式从数据库中检索相关信息块(Chunk)。
- Re-rank: 对检索到的信息块进行重新排序,以提高相关性。
- Answer: 结合重新排序后的信息块,生成最终的答案。
4. LLMs(大型语言模型)
- 与“Answer”模块交互,用于生成最终的答案。大型语言模型负责理解和生成自然语言的回答。
5. 数据库
- 存储检索到的信息块(Chunk),这些信息块通过关键词和嵌入进行索引,以便快速检索。
6. 任务执行组件(Task Executor)
- Document Parser: 解析文档内容,提取文本信息。
- OCR: 光学字符识别,用于处理图像中的文本信息。
- Document Layout Analyze: 分析文档的布局结构,提取表格、段落等信息。
- Table Structure Recognition: 识别表格结构,提取表格数据。
7. 流程说明
-
问题输入:
- 用户通过Web Nginx输入问题。
- API Server中的Query Analyze模块对问题进行分析,提取关键词并生成问题的嵌入向量。
-
任务分发:
- Task Dispatch模块根据问题的类型和内容,分发相应的任务(例如文档解析、OCR等)。
-
信息检索:
- Multi-way Recall模块通过关键词和嵌入向量从数据库中检索相关的信息块(Chunk)。
-
重新排序:
- Re-rank模块对检索到的信息块进行重新排序,以确保最相关的信息排在前面。
-
答案生成:
- Answer模块结合重新排序后的信息块,利用LLMs生成最终的答案。
-
文档处理:
- 对于上传的文档,系统会通过Document Parser、OCR、Document Layout Analyze和Table Structure Recognition等模块进行处理,提取有用的信息并存储到数据库中。
总结
这个RAG系统结合了检索和生成的能力:
- 通过检索模块从大量数据中找到相关信息。
- 利用大型语言模型生成自然语言的答案。
- 同时支持文档解析和图像处理,能够处理多种格式的输入数据。
这种架构适用于需要结合外部知识和生成能力的问答系统,特别是在处理专业文档或非结构化数据时非常有效。